Esta es la Parte 9 de la serie AD DFIR Lab. La Parte 8 nos dejó un snapshot noisy-ad-current con 2 años de narrativa realista. La Parte 9 saca ese snapshot como imagen forense, intacta y lista para análisis.
El puente entre “lab listo” y “respuestas forenses”
Cuando terminó la Parte 8, el lab tenía un snapshot ZFS llamado noisy-ad-current en cada VM con ~21k markers de actividad persona-driven, ~1.3 millones de eventos EVTX backdated en 2 años, ficheros Prefetch, timestamps NTFS, todo. Un dataset sintético completo.
Pero un snapshot viviendo dentro de Proxmox no es una imagen forense. Es un block device vivo gestionado por ZFS. Para poder analizarlo de verdad con herramientas como masstin, chainsaw, Plaso, Volatility, FTK Imager o Autopsy, necesitas el contenido del disco como fichero — una imagen raw, un E01, un VMDK. Algo que tu laptop forense pueda leer.
Así que la Parte 9 es el puente: cómo sacar el estado del disco de cada VM desde el host Proxmox de Hetzner hasta tu máquina local de análisis como imagen forense, con las tres restricciones habituales:
- Consistencia — la imagen debe representar un estado punto-en-el-tiempo único, no una mezcla smeared
- Sin downtime — el lab debe seguir corriendo; la imagen no puede forzar apagones de VMs
- Presupuesto de disco ajustado — el host Proxmox tiene espacio limitado; no puedes permitirte volcar 320 GB en local antes de transferirlos
La solución que cumple los tres requisitos resultó ser pequeña y elegante. Te explico por qué cada pieza, y luego enseño un benchmark real de imagen de las 7 VMs.
El enfoque naïve que los tutoriales DFIR suelen enseñar
Una imagen forense clásica de un host Windows corriendo se hace más o menos así:
# Apagar la VM limpiamente
qm shutdown 106
# Esperar a que pare
# ...y ahora dd sobre el block device
dd if=/dev/vm-106-disk bs=16M of=/tmp/vm-106.raw
# Copiar a la máquina de análisis
scp /tmp/vm-106.raw yo@laptop:/mnt/casos/
Tres pasos, tres problemas para nuestro lab:
Problema 1 — downtime forzado. Apagar cada VM para imaginarla significa que el lab se cae. Si estás intentando simular un ejercicio de incident response o capturar estado mientras algo está corriendo, eso invalida el propósito.
Problema 2 — staging intermedio. dd if=... of=/tmp/... escribe la imagen raw completa al disco local de Proxmox primero. Para un zvol Windows de 50 GB, eso son 50 GB de storage temporal. Multiplicado por 7 VMs, necesitas 320 GB de scratch space en el host. La partición root de Proxmox en nuestro lab tiene ~13 GB libres. Esto la llenaría instantáneamente y bloquearía el host.
Problema 3 — transferencia lenta. Sin comprimir, mover 320 GB por el cable a ~13 MB/s (el ancho de banda sostenido que medí) tarda 6.8 horas. Irrazonable para un workflow que quieres correr antes de cada sesión de ataque.
Claramente, no. Vamos al enfoque que sí funciona.
El enfoque real: snapshots ZFS, clones, compresión en stream
Dos primitivas de ZFS hacen el trabajo pesado.
Primitiva 1 — los snapshots ZFS son vistas read-only punto-en-el-tiempo de un zvol. Ya tenemos esto desde la Fase 10: noisy-ad-current es un snapshot del disco de cada VM capturado en un momento específico. La VM sigue escribiendo a su estado live después del snapshot, pero el snapshot en sí está congelado e inmutable. Esto es exactamente la propiedad de “consistencia” que la forense necesita — sin smearing, sin actualizaciones parciales. Tomar un filesystem en el momento de un snapshot ZFS es equivalente a una “imagen pull-the-plug” de un host corriendo en ese momento, sin tirar del cable.
Primitiva 2 — los clones ZFS de snapshots son instantáneos y esencialmente gratis. Un clone ZFS coge un snapshot y lo expone como un zvol escribible nuevo, compartiendo bloques con el snapshot vía copy-on-write. Crear un clone es una operación O(1) de metadata — milisegundos, cero disco extra.
# Clonar el snapshot a un device nuevo
zfs clone vmstore/images/vm-106-disk-0@noisy-ad-current \
vmstore/images/vm-106-forensic-tmp
# Ahora /dev/zvol/vmstore/images/vm-106-forensic-tmp existe como block device
# con exactamente el estado del snapshot
ls -l /dev/zvol/vmstore/images/vm-106-forensic-tmp
# -> brw-rw---- 1 root disk 230, 8 Apr 15 02:29 /dev/zvol/...
Combinando las dos: para conseguir una imagen consistente de una VM sin tocar el disco vivo, clonas el snapshot → lees el clone con dd → destruyes el clone. La VM viva no se entera. Sin downtime.
Y en vez de volcar a un fichero scratch en el host Proxmox, pipeamos el output de dd por zstd (compresión) por SSH (transporte de red) y aterriza directamente en el disco del laptop del analista. El host Proxmox lee bloques de ZFS, los comprime al vuelo, los manda por el túnel, y nunca escribe nada a su propio filesystem durante el dump. Cero footprint en Hetzner.
# Desde el laptop del analista:
ssh root@hetzner "
zfs clone vmstore/images/vm-106-disk-0@noisy-ad-current \
vmstore/images/vm-106-forensic-tmp
dd if=/dev/zvol/vmstore/images/vm-106-forensic-tmp bs=16M status=none \
| zstd -T0 -10
zfs destroy vmstore/images/vm-106-forensic-tmp
" > /mnt/forensic/vm-106-ws01.raw.zst
Esa es toda la técnica en un comando. El resto del post explica por qué elegimos cada pieza.
Por qué raw + zstd y no E01 / qcow2 / VMDK
masstin — la herramienta que escribí para forense de movimiento lateral — maneja cuatro formatos de imagen nativamente. Lo comprobé con un caso real de 109 imágenes:
=> Image 2/109: GUR00250622D.dd (DD, 119.2 GB) ← raw dd
=> Image 3/109: E01Capture.E01 (E01, 3.9 GB) ← EnCase/libewf
=> Image 4/109: STFDC01_2016.vmdk (VMDK, 100.0 GB) ← VMware
=> Image 46/109: win10-2004.vmdk (VMDK, 60.0 GB)
Así que la elección del formato no es una restricción de masstin — es por tamaño, velocidad y simplicidad operativa. Aquí cómo quedan las alternativas para un zvol Windows de 50 GB con ~10 GB usados:
| Formato | Tamaño | Tiempo | masstin | Notas |
|---|---|---|---|---|
| dd sin comprimir | 50 GB | ~50s en disco | ✓ | Inviable por el cable |
| raw + zstd -10 | ~5 GB | ~7 min | ✓ | Elegido |
| raw + zstd -19 | ~3.5 GB | ~14 min | ✓ | Solo vale la pena en enlaces rápidos |
| qcow2 comprimido | ~5 GB | ~2 min | ✗ | Necesita conversión para algunas tools |
| E01 default | ~5.5 GB | ~5 min | ✓ | Ligeramente más grande |
| E01 max compression | ~5 GB | ~10 min | ✓ | Mismo tamaño que zstd, 3x más lento |
zstd -10 gana en todos los ejes excepto en metadatos de cadena de custodia. El matiz es que E01 tiene hashes SHA1 baked in como parte del formato del fichero, con metadata sobre la herramienta de adquisición, timestamps y operador. Si estás imaginando una máquina real que puede acabar en un juicio, eso importa. Para un lab de training, es ruido.
Me fui con raw + zstd por dos razones prácticas:
-
El algoritmo de compresión de zstd es objetivamente mejor que el zlib de E01 para esta workload. zlib es de 1995. zstd es de 2015. Mismo input, zstd produce un output más pequeño, más rápido, en todos los datasets comunes. Nuestros zvols Windows Server comprimen al ~13% de su
volsizecon zstd -10. zlib en E01 a máxima compresión hace plateau en ~10%, pero tarda 3-5x más en llegar ahí. -
raw es universal. Toda herramienta forense del planeta abre
dd.raw. Puedeslosetupearlo,mmlsearlo,flsearlo, dárselo a Autopsy, chainsaw, masstin, X-Ways, FTK Imager. Cero conversión. E01 y VMDK requieren herramientas format-aware..raw.zstse descomprime con un solozstd -dy ya es una imagen de disco.
Si un caso específico más adelante exige metadata E01, libewf-utils incluye ewfacquire, que puede leer desde el mismo device del clone ZFS y producir un E01 con metadata de adquisición propia. Son 10 líneas de adición al script cuando lo necesitemos.
El script
scripts/lab-forensic-dump.sh. Tres subcomandos:
lab-forensic-dump.sh estimate [vmid ...]
Predice tamaños de dump (sin I/O en block devices)
lab-forensic-dump.sh dump <vmid> <snapshot> [--level N]
Stream raw+zstd a stdout (para uso por pipe SSH)
lab-forensic-dump.sh local <vmid> <snapshot> <output> [--level N]
Escribe a fichero local en Proxmox + sidecar SHA256
El subcomando dump es el interesante porque es la pieza que corre dentro del túnel SSH. Está diseñado para tener cero footprint en el host Proxmox: el clone es ZFS-cheap, el pipe de dd nunca escribe a disco en Proxmox, y el clone se destruye vía trap de bash independientemente de cómo salga la función (éxito, error o signal interrupt).
Aquí el core del script:
do_dump() {
local vmid="$1"
local snap="$2"
local level="$3"
local source="${POOL}/vm-${vmid}-disk-0@${snap}"
zfs list -H -t snapshot "$source" >/dev/null 2>&1 \
|| die "snapshot not found: $source"
# Nombre fijo por VM para que los clones orphan de runs anteriores
# sean reutilizados en vez de acumularse
local clone="${POOL}/vm-${vmid}-forensic-tmp"
# Destruir clone stale si está (run anterior murió antes de cleanup)
if zfs list -H "$clone" >/dev/null 2>&1; then
log "removing stale clone: $clone"
zfs destroy "$clone" || die "couldn't destroy stale clone"
fi
log "cloning $source -> $clone"
zfs clone "$source" "$clone" || die "zfs clone failed"
CLONE="$clone" # registrar para trap EXIT cleanup
local zvol_device="/dev/zvol/${clone}"
# Esperar a que udev cree el node del device (hasta 10s)
for _ in $(seq 1 20); do
[ -b "$zvol_device" ] && break
sleep 0.5
done
log "dumping $zvol_device with zstd -T0 -${level}"
dd if="$zvol_device" bs="16M" status=none 2>/dev/null \
| zstd -T0 "-${level}" --quiet
local rc zst_rc
rc=${PIPESTATUS[0]}
zst_rc=${PIPESTATUS[1]:-0}
zfs destroy "$clone" 2>/dev/null || true
CLONE=""
[ "$rc" -eq 0 ] && [ "$zst_rc" -eq 0 ] || die "dump failed rc=$rc zst=$zst_rc"
}
Un par de detalles que merecen mención:
-
Nombre de clone fijo (
vm-${vmid}-forensic-tmp) en vez de un nombre basado en PID. Esto significa que si un run anterior murió mid-dump y dejó un clone, el siguiente run simplemente lo destruye y empieza limpio. Los nombres basados en PID se acumularían para siempre. -
PIPESTATUS[0]yPIPESTATUS[1]capturados en una única declaración. El arrayPIPESTATUSde bash se resetea por cada comando, incluidolocal. Si escribes dos declaracioneslocalback to back, la segunda encuentraPIPESTATUSvacío y bajoset -ubash explota con “unbound variable”. El fix es capturar ambos valores en variables locales pre-declaradas primero, o usar una asignación única. Tuve que aprenderlo por las malas en el primer test run. -
Trap cleanup a nivel de script:
CLONE="" cleanup_clone() { [ -n "$CLONE" ] && zfs destroy "$CLONE" 2>/dev/null } trap cleanup_clone EXIT INT TERMPase lo que pase — exit limpio, error, Ctrl+C, SIGTERM — el trap corre y destruye cualquier clone que estemos rastreando. Esta es la diferencia entre “siempre hay un clone orphan por ahí” y “nunca hay un clone orphan”.
El subcomando estimate
Antes de hacer dump, quieres saber cuánto espacio va a necesitar el output en el laptop del analista. ZFS nos lo dice directamente:
zfs get -Hp volsize,referenced vmstore/images/vm-101-disk-0
volsize= lo que la VM ve como su disco (50 GB para nuestros Windows VMs)referenced= datos reales allocated (mucho más pequeño, porque thin-provisioned)
A partir de estos podemos predecir el tamaño comprimido con un ratio simple. Inicialmente pensé referenced × 0.4 basándome en folklore sobre ratios de zstd para datos generales. El benchmark real mostró que estaba mal — para nuestras Windows Server VMs con 2 años de actividad phase10, el ratio real está más cerca de 0.7.
¿Por qué mayor que mi estimate? Porque los ficheros EVTX que generamos tienen alta entropía. Cada evento tiene un timestamp único (al microsegundo), Event Record IDs únicos, GUIDs únicos en muchos campos, SIDs de usuario, SIDs de máquina. Eso es información que el compresor no puede squeeze. La metadata NTFS y los system files de Windows comprimen razonablemente (~50-60%), pero el ruido generado es básicamente incomprimible.
Linux sale en ~0.6 porque ext4 es más denso y hay menos entropía en la actividad generada.
El estimate ahora usa used × 0.7 universalmente. Sobre-predice Linux ligeramente (más seguro que sub-predecir) y matchea Windows con precisión:
VMID NAME VOLSIZE USED EST-ZST
----------------------------------------------------------------------
101 DC01-kingslanding 50GB 8.0GB ~5.6GB
102 DC02-winterfell 50GB 8.1GB ~5.7GB
103 SRV02-castelblack 50GB 12GB ~8.1GB
104 DC03-meereen 50GB 8.7GB ~6.1GB
105 SRV03-braavos 50GB 9.3GB ~6.5GB
106 WS01-highgarden 50GB 14GB ~9.4GB
107 LNX01-oldtown 20GB 1.4GB ~940MB
----------------------------------------------------------------------
TOTAL 320GB 60GB ~42GB
320 GB de volsize, 60 GB de referenced, ~42 GB comprimido. El ratio de compresión contra volsize es ~13%, lo que significa que encogemos el tráfico del cable de “demasiado lento para ser práctico” a “acaba en un descanso de comida”.
El benchmark real — las 7 VMs imaginadas en una sesión
Corrí el pipeline completo end-to-end el 2026-04-15, streameando cada VM por SSH desde Hetzner (95.217.226.229, Alemania) a un disco forense de mi laptop en España. El loop:
OUTDIR="/i/forensic/lab-$(date -u +%Y-%m-%d)"
mkdir -p "$OUTDIR"
for vm in 101 102 103 104 105 106 107; do
ssh root@95.217.226.229 \
"/root/lab/scripts/lab-forensic-dump.sh dump $vm noisy-ad-current" \
> "$OUTDIR/vm-${vm}.raw.zst"
done
Resultados:
| VM | Nombre | Comprimido | Tiempo | Throughput |
|---|---|---|---|---|
| 101 | DC01-kingslanding | 5.4 GB | 6m 40s | 13 MB/s |
| 102 | DC02-winterfell | 5.5 GB | 7m 00s | 13 MB/s |
| 103 | SRV02-castelblack | 8.0 GB | 9m 45s | 13 MB/s |
| 104 | DC03-meereen | 5.8 GB | 7m 10s | 13 MB/s |
| 105 | SRV03-braavos | 6.4 GB | 8m 11s | 13 MB/s |
| 106 | WS01-highgarden | 9.8 GB | 12m 11s | 13 MB/s |
| 107 | LNX01-oldtown | 840 MB | 1m 33s | 9 MB/s |
| Total | 42 GB | 52m 34s |
SHA256 de cada fichero comprimido capturados en hashes.sha256, timestamps logueados a benchmark.log. Todo el asunto tardó 52 minutos y 34 segundos, end-to-end, con mi laptop sin hacer nada durante la espera.
Tres observaciones del run real.
El cuello de botella es la red, no la CPU
Cada VM Windows rindió a exactamente 13 MB/s — eso son ~100 Mbit/s sostenidos. El clone es instantáneo, el dd lee ZFS a >1 GB/s (NVMe), y zstd -T0 -10 multithreaded corre a ~500 MB/s en la CPU del host Proxmox. Así que la CPU está idle el 95% del dump. Lo único que está trabajando duro es el túnel SSH piping los bytes comprimidos por Internet hacia mi laptop.
Esto importa para tunear. Subir zstd a -19 NO haría el dump más rápido. Solo haría el stream comprimido más pequeño, pero como ya estamos limitados por la velocidad de red y no por lo rápido que Proxmox puede empujar bytes, gastar ciclos extra de CPU en mejor compresión no ayuda al wall clock time en absoluto. Solo ayudaría en un enlace simétrico de 1 Gbit+ donde zstd se convierte en el bottleneck en vez del pipe.
Si estás en un enlace más rápido que el mío (host colocated, fibra a fibra, 200+ Mbit/s), querrías reconsiderarlo. En mi enlace de 100 Mbit/s, -10 está bien.
Los VMs Windows Server clusterean alrededor de 6 GB, WS01 y SRV02 son outliers
Los tres DCs (101, 102, 104) salieron a 5.4-5.8 GB. El servidor ADCS (105) a 6.4 GB. SRV02 (103) a 8.0 GB, y WS01 (106) a 9.8 GB.
El ranking refleja cuánto actividad de Fase 10 tocó cada VM:
- WS01 es el más pesado porque es la única workstation Windows 10, y jon.snow la usó cada día laborable durante 2 años simulados. Dos años de Prefetch, estado de perfil de usuario, trazas de proceso Chrome, crecimiento del hive de usuario. Una workstation acumula mucho más contenido distinto que un DC.
- SRV02 es el segundo porque aloja a 4 personas humanas más el job system.backup — cada día de la narrativa generó múltiples eventos por round en este VM de 5 usuarios distintos. También corre IIS y MSSQL en background.
- Los DCs reciben solo
system.replicationpara sus dominios respectivos + un par de auths cross-forest. Volumen similar por DC. - SRV03 (ADCS) recibe system.adcs cada round pero nada más.
- LNX01 es pequeño porque su volsize es 20 GB (vs 50 en Windows) y Linux empaqueta sus ficheros densamente con menos espacio vacío.
Esto es una buena señal de validación de que la Fase 10 generó la distribución de actividad que diseñé en personas.yaml. Los tamaños son proporcionales al conteo de personas y la carga de actividad per-persona para cada VM.
El fichero de hashes se cortó mid-write en el primer intento
Pequeña lección operativa. El paso final de mi script de benchmark era:
echo "=== SHA256 ===" >> "$BENCH"
cd "$OUTDIR" && sha256sum *.raw.zst | tee hashes.sha256
La redirección por tee crea hashes.sha256 pero los writes son line-buffered en la mayoría de shells. Si leo el fichero demasiado pronto, veo solo las primeras líneas. Eso es lo que pasó en la primera revisión: 4 de 7 hashes en el fichero aunque el benchmark.log ya tenía los 7.
Re-corriendo sha256sum directamente produjo el fichero completo. No es un bug real, solo timing. Pero es un recordatorio útil de que “la tarea se completó” y “todos los ficheros intermedios están totalmente flusheados a disco” no son exactamente el mismo momento.
Lo que hay en el laptop ahora
/i/forensic/lab-2026-04-15/
├── benchmark.log 1.8 KB (log completo de la sesión con timings)
├── hashes.sha256 620 B (7 hashes SHA256, verificados)
├── vm-101.raw.zst 5.4 GB
├── vm-101.stderr 247 B (log sidecar del script Proxmox-side)
├── vm-102.raw.zst 5.5 GB
├── vm-102.stderr 247 B
├── vm-103.raw.zst 8.0 GB
├── vm-103.stderr 247 B
├── vm-104.raw.zst 5.8 GB
├── vm-104.stderr 247 B
├── vm-105.raw.zst 6.4 GB
├── vm-105.stderr 247 B
├── vm-106.raw.zst 9.8 GB
├── vm-106.stderr 247 B
├── vm-107.raw.zst 840 MB
└── vm-107.stderr 202 B
42 GB totales. El disco del laptop tiene aún 780 GB libres, así que hay mucho espacio para descomprimir, procesar, y mantener tanto el archivo .zst como los ficheros .raw extraídos uno al lado del otro.
Siguiente paso: descomprimir y correr masstin en modo bulk:
cd /i/forensic/lab-2026-04-15
# Descomprimir en sitio, removiendo el .zst tras cada fichero para mantener
# el pico de footprint plano en vez de duplicado
for f in *.raw.zst; do
zstd -d --rm "$f"
done
# Correr masstin en todo el directorio
masstin -a parse-massive -d . -o masstin-output.csv --overwrite
Eso produce un CSV unificado con todos los eventos de movimiento lateral que masstin puede extraer a través de las 7 imágenes: logons, sesiones SMB, trazas WinRM/WMI/PsExec, tickets Kerberos, writes a registry MountPoints2, triggers de scheduled task remotos, y el resto del toolkit. En nuestro caso: 256,237 eventos de autenticación y movimiento lateral a través de 30+ cuentas de usuario en los 3 dominios.
El output está diseñado para cargarse en Neo4j o Memgraph para caza basada en grafo. Aquí el resultado de cargar el timeline completo del lab en Memgraph — cada nodo es una máquina, cada arista una autenticación o conexión lateral:
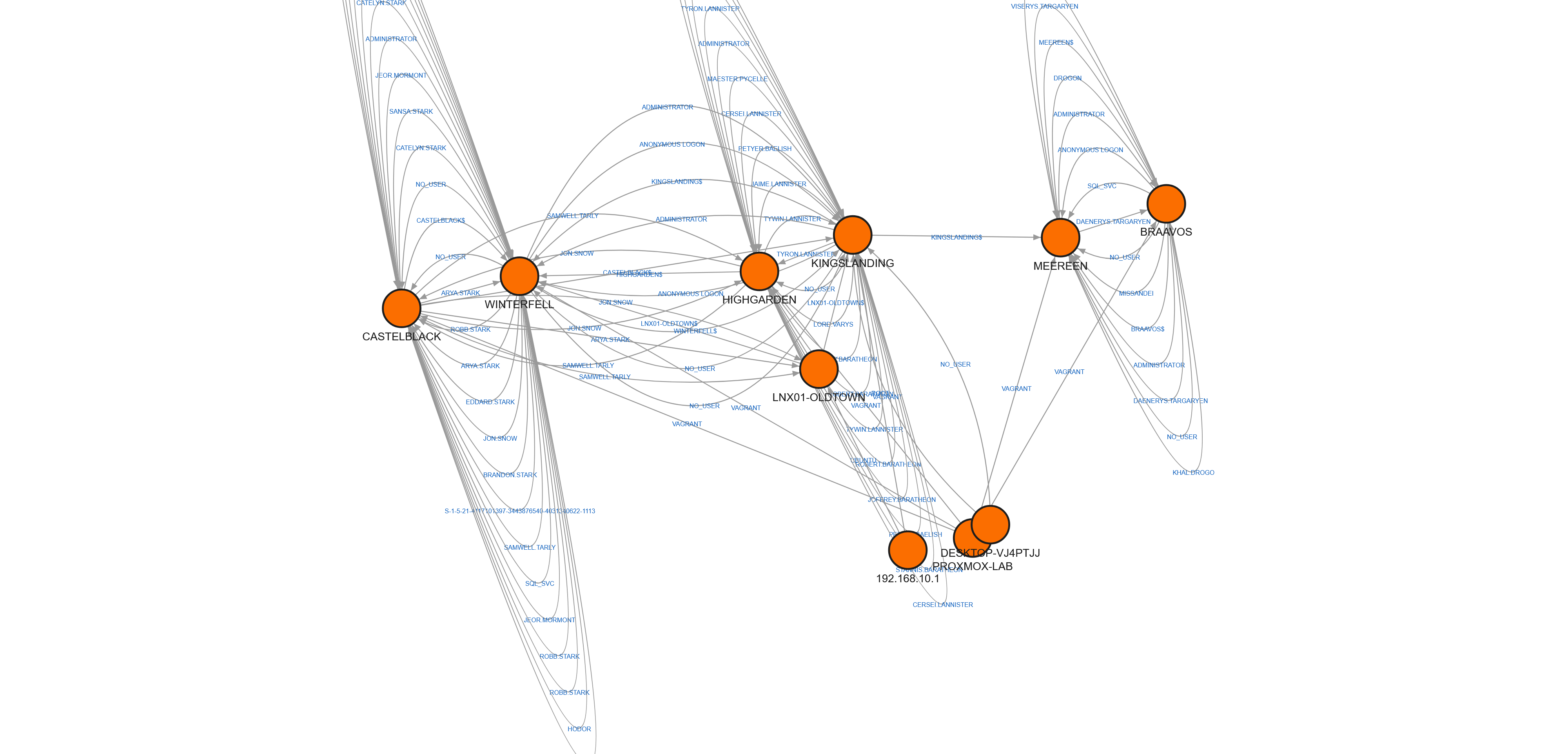
Los clusters densos en la parte superior son los Domain Controllers — miles de autenticaciones Kerberos cruzadas entre los tres dominios. Los nodos con menos aristas abajo son las workstations y servers miembro. Esta es la topología real de dos años de actividad corporativa simulada, lista para que un atacante deje su huella encima.
Pero eso es la Parte 10. La Parte 9 acaba aquí, con un pipeline validado y un dataset real encima de mi mesa.
Lo que viene
La Parte 10 — “Fuego y Sangre: Escenarios de Ataque y Análisis Forense” — correrá ataques desde Kali sobre un rollback fresco de noisy-ad-current, re-imagenearemos con este pipeline, y dejaremos que masstin mastique el par antes/después para ver qué artefactos realmente cazan al atacante.
El pipeline de imaging es la herramienta. Los ataques son lo que lo hace útil.
Siguiente: Parte 10 — Fuego y Sangre: Escenarios de Ataque y Análisis Forense (próximamente)
Anterior: Parte 8 — Un Día en el Reino: Generando Dos Años de Ruido Histórico
$ comments