Por qué visualizar en grafos
Cuando tienes 50 máquinas, miles de logons y necesitas encontrar por dónde se movió el atacante, un CSV no es suficiente. Necesitas ver las relaciones — qué máquina se conectó a cuál, con qué usuario, y cuándo.
Neo4j convierte la timeline de masstin en un grafo interactivo donde cada máquina es un nodo y cada conexión lateral es una arista. Esto te permite ver patrones que en una tabla serían invisibles.
Transformaciones de datos
Masstin preserva los valores originales de la evidencia en la medida de lo posible. Los nombres de nodos (hostnames, IPs) y propiedades se almacenan sin transformación — SRV-FILE01 se mantiene como SRV-FILE01, 10.10.1.50 se mantiene como 10.10.1.50.
La única transformación se aplica a los tipos de relación (la etiqueta del edge, que representa la cuenta de usuario). Es una restricción del lenguaje Cypher — los tipos de relación deben ser identificadores válidos y no pueden contener puntos, guiones ni empezar por un número:
| Qué | Transformación | Ejemplo |
|---|---|---|
| Tipo de relación (usuario) | Puntos, guiones, espacios → _, MAYÚSCULAS, eliminar @dominio |
j.garcia@ACME.LOCAL → J_GARCIA |
| Nombres de nodo (hostnames, IPs) | Sin transformación — valor original | SRV-FILE01 se mantiene SRV-FILE01 |
| Propiedades (src_ip, etc.) | Sin transformación — valor original | 10.10.1.50 se mantiene 10.10.1.50 |
| Usuarios en propiedades | Solo se elimina el sufijo @dominio |
j.garcia@ACME.LOCAL → j.garcia |
Al escribir queries, usa los valores originales para nombres de nodos y propiedades, y la forma normalizada solo para los tipos de relación.
El poder del filtrado temporal
Esta es la característica más valiosa de la visualización con masstin y Neo4j.
Masstin agrupa las conexiones por máquina origen, máquina destino, usuario y tipo de logon, y almacena la fecha más antigua de cada grupo. Esto significa que cuando filtras por rango temporal, automáticamente eliminas todas las conexiones que ya existían antes de ese periodo.
¿Por qué es esto tan importante? En una respuesta ante incidentes, la red está llena de movimiento lateral legítimo: cuentas de servicio, administradores haciendo su trabajo, usuarios accediendo a recursos compartidos. Todo ese ruido ha estado ahí durante meses. Pero las conexiones del atacante son nuevas.
Al filtrar por el periodo en el que sospechas que comenzó el ataque, todo el ruido histórico desaparece y solo quedan las conexiones que se vieron por primera vez en esa ventana temporal. En cuestión de segundos pasas de un grafo ilegible a un mapa claro del movimiento del atacante.
Instalación de Neo4j
| Plataforma | Instalación |
|---|---|
| Windows | Descarga desde neo4j.com/download. Instala Neo4j Desktop, crea una base de datos e iníciala. Accede al browser en http://localhost:7474 |
| Linux | sudo apt install neo4j o descarga desde neo4j.com/download. Inicia con sudo systemctl start neo4j. Accede en http://localhost:7474 |
| macOS | brew install neo4j o descarga desde neo4j.com/download. Inicia con neo4j start. Accede en http://localhost:7474 |
| Docker | docker run -p 7474:7474 -p 7687:7687 -e NEO4J_AUTH=neo4j/password neo4j |
Carga los datos con:
masstin -a load-neo4j -f timeline.csv --database localhost:7687 --user neo4j
Dos modos de carga: agrupado vs sin agrupar
El cargador tiene dos modos que responden a preguntas distintas:
Agrupado (por defecto) produce una arista por cada combinación única (destino, usuario, logon_type), con una propiedad count que indica cuántos eventos se colapsaron y time con la fecha del primer evento. Es la foto global — quién habla con quién, con qué frecuencia y mediante qué tipo de logon. Ideal para entender la topología de la red, mapear fronteras de confianza y presentar hallazgos.
Sin agrupar (--ungrouped) produce una arista por cada fila del CSV, preservando el timestamp real de cada evento. Es el modo para hunting de caminos temporales — encontrar rutas de atacante cronológicamente coherentes donde cada salto ocurrió después del anterior. Siempre acotarlo con --start-time / --end-time; cargar un timeline completo de 250k filas sin agrupar generará un grafo inutilizable.
| Modo | Caso de uso | Aristas |
|---|---|---|
| Agrupado (defecto) | Vista global, topología, presentaciones | ~100-200 |
--ungrouped + ventana temporal |
Hunting de caminos temporales, timeline del incidente | 1 por evento |
Flags del cargador
| Flag | Qué hace |
|---|---|
--ungrouped |
Una arista por fila del CSV. Preserva timestamps reales para queries de caminos temporales. |
--start-time "YYYY-MM-DD HH:MM:SS" |
Descarta filas anteriores a este momento. |
--end-time "YYYY-MM-DD HH:MM:SS" |
Descarta filas posteriores a este momento. |
# Vista global (defecto) — quién habla con quién
masstin -a load-neo4j -f timeline.csv --database localhost:7687 --user neo4j
# Hunting temporal — cada evento en una ventana de 30 minutos
masstin -a load-neo4j -f timeline.csv --database localhost:7687 --user neo4j \
--ungrouped --start-time "2026-03-15 14:00:00" --end-time "2026-03-15 14:30:00"
Unificación de IP y nombre de host
Un mismo equipo físico aparece con frecuencia en distintos eventos, unas veces como IP y otras como hostname. masstin construye internamente un mapa de frecuencias y los resuelve a un único nodo del grafo de forma automática. Los eventos 4778 (Sesión Reconectada) y 4779 (Sesión Desconectada) reciben un peso x1000 en ese mapa porque Windows siempre rellena de forma fiable tanto el nombre de la estación como la IP en esos eventos — así que un solo 4778/4779 pesa más que cientos de eventos normales que pudieran contradecirlo. Las IPs externas de atacantes que no tienen sesión asociada simplemente se quedan como nodos IP.
Si después de cargar descubres que dos nodos siguen siendo el mismo equipo —por ejemplo porque tu dataset no tenía evidencias 4778/4779— puedes fusionarlos con la acción merge-neo4j-nodes que se muestra al final del artículo.
Queries Cypher
Ver todo el movimiento lateral
MATCH (h1:host)-[r]->(h2:host)
RETURN h1, r, h2
Filtrar por rango temporal
MATCH (h1:host)-[r]->(h2:host)
WHERE datetime(r.time) >= datetime("2026-03-12T00:00:00.000000000Z")
AND datetime(r.time) <= datetime("2026-03-13T00:00:00.000000000Z")
RETURN h1, r, h2
ORDER BY datetime(r.time)
Excluir cuentas de máquina y conexiones sin usuario
Las cuentas de máquina (terminadas en $) y las conexiones sin usuario resuelto (NO_USER) generan mucho ruido. Filtrarlas te deja solo movimiento lateral iniciado por personas:
MATCH (h1:host)-[r]->(h2:host)
WHERE datetime(r.time) >= datetime("2026-03-12T00:00:00.000000000Z")
AND datetime(r.time) <= datetime("2026-03-13T00:00:00.000000000Z")
AND NOT r.target_user_name ENDS WITH '$'
AND NOT r.target_user_name = 'NO_USER'
RETURN h1, r, h2
ORDER BY datetime(r.time)
Solo conexiones RDP (logon type 10)
MATCH (h1:host)-[r]->(h2:host)
WHERE datetime(r.time) >= datetime("2026-03-12T00:00:00.000000000Z")
AND datetime(r.time) <= datetime("2026-03-13T00:00:00.000000000Z")
AND NOT r.target_user_name ENDS WITH '$'
AND r.logon_type = '10'
RETURN h1, r, h2
ORDER BY datetime(r.time)
Solo conexiones de red (logon type 3 — SMB, PsExec, WMI)
MATCH (h1:host)-[r]->(h2:host)
WHERE datetime(r.time) >= datetime("2026-03-12T00:00:00.000000000Z")
AND datetime(r.time) <= datetime("2026-03-13T00:00:00.000000000Z")
AND NOT r.target_user_name ENDS WITH '$'
AND r.logon_type = '3'
RETURN h1, r, h2
ORDER BY datetime(r.time)
Cuentas de servicio por convención de nombres
Si tu organización usa un prefijo para cuentas de servicio (ej: SVC_):
MATCH (h1:host)-[r]->(h2:host)
WHERE datetime(r.time) >= datetime("2026-03-10T00:00:00.000000000Z")
AND datetime(r.time) <= datetime("2026-03-14T00:00:00.000000000Z")
AND (
r.target_user_name STARTS WITH 'SVC'
OR r.subject_user_name STARTS WITH 'SVC'
)
RETURN h1, r, h2
ORDER BY datetime(r.time)
Filtrar por usuarios, máquinas e IPs específicas
Cuando ya has identificado cuentas o máquinas sospechosas, esta query traza su actividad completa. Recuerda usar los valores transformados (guiones bajos, mayúsculas):
MATCH (h1:host)-[r]->(h2:host)
WHERE datetime(r.time) >= datetime("2026-03-12T00:00:00.000000000Z")
AND datetime(r.time) <= datetime("2026-03-13T00:00:00.000000000Z")
AND NOT r.target_user_name ENDS WITH '$'
AND NOT r.target_user_name = 'NO_USER'
AND r.logon_type IN ['3', '10']
AND (
(h1.name = 'WS_HR02' OR h2.name = 'WS_HR02')
OR r.target_user_name IN ['ADM_DOMAIN', 'M_LOPEZ']
OR r.subject_user_name IN ['ADM_DOMAIN', 'M_LOPEZ']
OR r.src_ip IN ['10_99_88_77', '10_10_1_80']
)
RETURN h1, r, h2
ORDER BY datetime(r.time)
Rastrear a un usuario concreto
MATCH (h1:host)-[r]->(h2:host)
WHERE r.target_user_name = 'ADM_DOMAIN'
RETURN h1, r, h2
ORDER BY datetime(r.time)
Nodos más conectados (objetivos o puntos de pivoting)
Identifica qué máquinas tienen más conexiones entrantes:
MATCH (h1:host)-[r]->(h2:host)
RETURN h2.name AS target, COUNT(r) AS connections
ORDER BY connections DESC
LIMIT 10
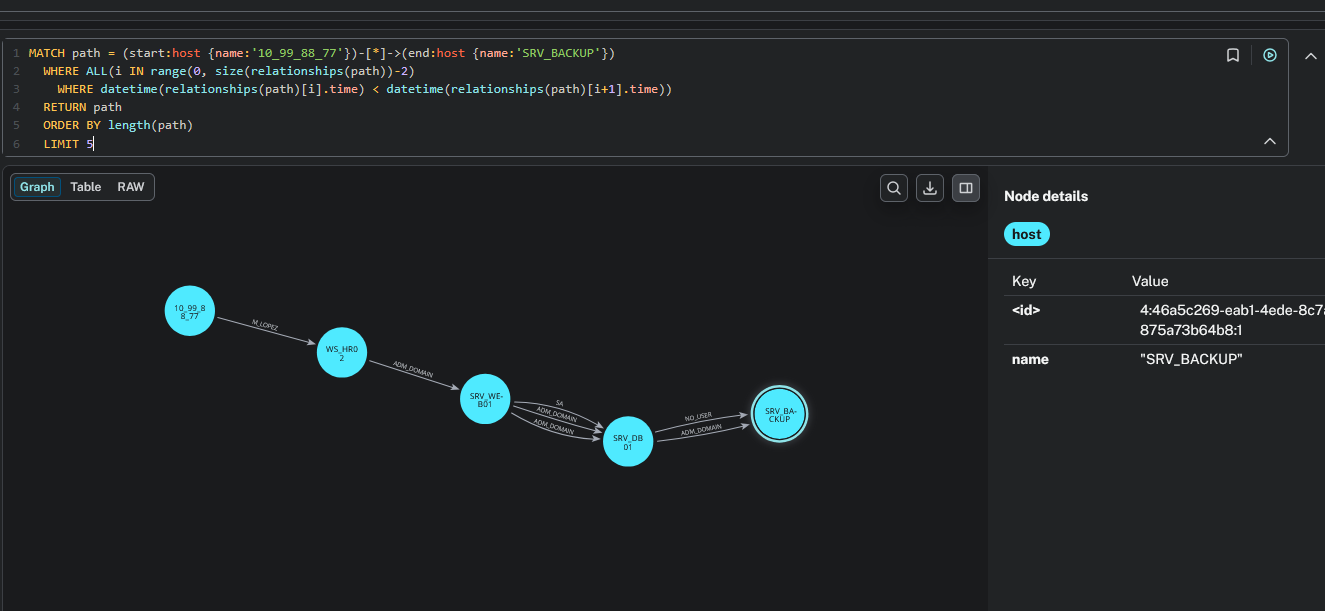
Camino temporal entre dos hosts
Esta es una de las queries más potentes para la reconstrucción de incidentes. Encuentra todos los caminos entre dos hosts donde cada salto es cronológicamente posterior al anterior — dándote la cadena real del ataque tal como ocurrió en el tiempo:
MATCH path = (start:host {name:'10_99_88_77'})-[*]->(end:host {name:'SRV_BACKUP'})
WHERE ALL(i IN range(0, size(relationships(path))-2)
WHERE datetime(relationships(path)[i].time) < datetime(relationships(path)[i+1].time))
RETURN path
ORDER BY length(path)
LIMIT 5
Reemplaza los nombres de host de inicio y fin con los tuyos. El resultado muestra la progresión del atacante a través de la red, validada temporalmente:
Post-carga: fusionar dos nodos que son el mismo equipo físico
A veces el cargador no logra atar un nodo en forma de IP con su gemelo en forma de hostname — normalmente porque el dataset no contenía eventos 4778 o 4779 de Security que actúen como evidencia autoritativa. masstin incluye una acción merge-neo4j-nodes que fusiona ambos nodos en uno, transfiriendo cada relación del nodo viejo al nuevo, preservando el tipo de relación y sus propiedades, y borrando después el nodo huérfano. No requiere APOC.
masstin -a merge-neo4j-nodes \
--database bolt://localhost:7687 --user neo4j \
--old-node "10.0.0.10" --new-node "WORKSTATION-A"
Internamente, masstin descubre los tipos de relación que tocan al nodo viejo y ejecuta una query de transferencia por cada tipo — porque Cypher vanilla no permite tipos de relación dinámicos en CREATE, y masstin produce un tipo por cada target_user_name. Si prefieres ejecutar el Cypher a mano para un tipo concreto :RELTYPE, el patrón es:
// Aristas SALIENTES de un tipo concreto
MATCH (new:host {name:'WORKSTATION-A'})
WITH new
MATCH (old:host {name:'10.0.0.10'})-[r:RELTYPE]->(target)
CREATE (new)-[nr:RELTYPE]->(target)
SET nr = properties(r)
DELETE r;
// Aristas ENTRANTES del mismo tipo
MATCH (new:host {name:'WORKSTATION-A'})
WITH new
MATCH (source)-[r:RELTYPE]->(old:host {name:'10.0.0.10'})
CREATE (source)-[nr:RELTYPE]->(new)
SET nr = properties(r)
DELETE r;
// Borrar el nodo huérfano una vez que ya no tiene aristas
MATCH (old:host {name:'10.0.0.10'}) DELETE old;
Si tienes APOC instalado, el equivalente en una sola línea es CALL apoc.refactor.mergeNodes([new, old], {properties:'combine', mergeRels:false}). La acción de masstin cubre el caso en que APOC no está disponible, que es lo habitual en una instalación recién hecha.
$ comments